The data shown above are the MFCC coefficients that we collected to classify one of our audio input files.
For this project we will be using MFCC as a means to identify the phonemes in the audio files. To collect
this data we used a built in Matlab Toolbox which computes the coefficients when you input an audio file.
We will be using the toolbox to collect all the coefficients which is a majority of our data for all the
audio files we will use.
Progress Report
1) Plots and Data
MFCC Coefficents

Spectrogram of Phoneme
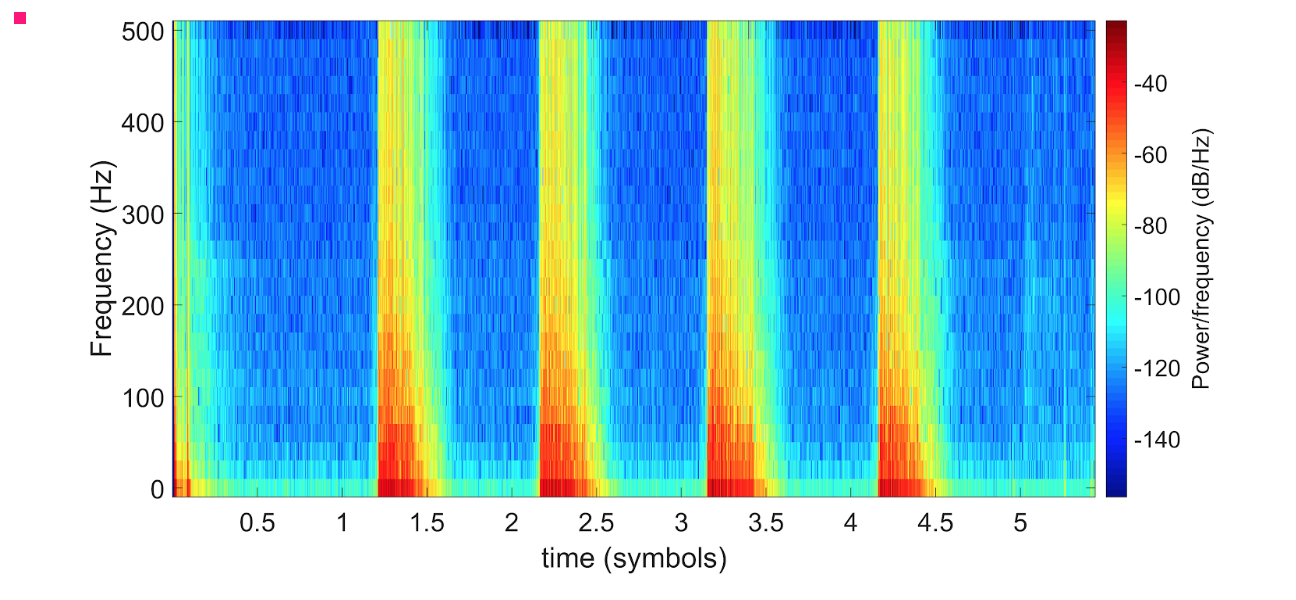
This plot shows a spectrogram of a given phoneme which is another tool we can use to identify phonemes.
While we will probably not collect spectrograms for each phoneme, spectral analysis is included in the MFCC
calculation so that will account for this procedure. However it is valuable to be able to see the spectrograms
of the different phonemes so we may come back to this in the future.
DTW - Dynamically Time Warped Signal Plot
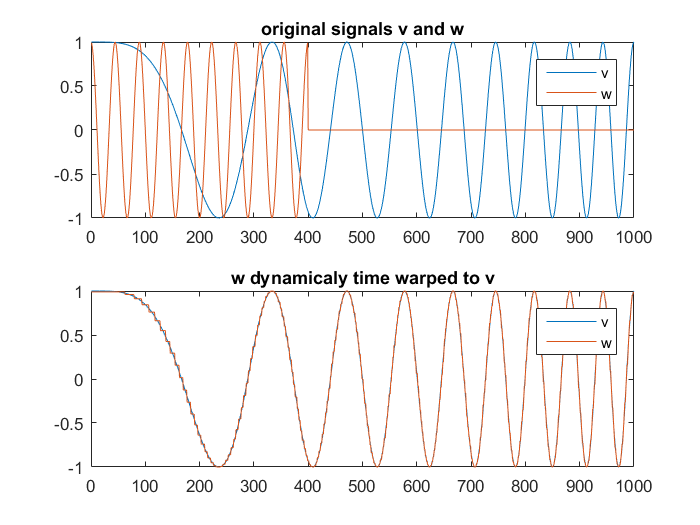
The plot shown here is the result of applying the Dynamic Time Warping toolbox of matlab to adjust for time
skew in different audio signals. This procedure will be very useful when are trying to morph a given song
using phonemes from another audio input. There will likely be some skew in the mapping procedure and this
action will correct the skew. So far we have just experimented with using the toolbox using various audio
files but we will soon employ with our actual audio data once we collect enough samples.
2) Progress and Challenges
So far we have done a lot of research reading various papers and projects about how to do phoneme translation
and being able to collect a set of phonemes from an audio file and translate it to the phonemes in another audio
file. We have determined that our data set will come from a collection of the 44 phonemes in the english language.
We can produce this dataset from a phrase which contains all of the phonemes. And we plan to either record someone
saying the phrase or just use a pre existing audio file of the phrase.
The work that we have done up to this point is organizing at a high level what are the goals for this project and
what are the various information/stages required to reach them. We began by performing some spectral analysis to
look at the phonemes and see how to discern between them. While this provides some valuable insights it does not
seem adequate to compare phonemes of different audio files and build a mapping between them.
Therefore we began looking into another form of characterizing audio files which is MFCC or Mel Frequency Cepstral
Coefficients which is a procedure that generates unique coefficients that can be used at differentiating between
phonemes.
We did notice some challenges selecting and applying the right classification algorithms when we are actually
trying to identify phonemes. It is difficult for us to evaluate the various algorithms because we don’t have much
machine learning background. For now we plan to try various algorithms like K-nearest neighbors and some Bayesian
techniques as well as some built in matlab toolboxes to assist in this task.
3) Plan
After determining the goals and scope of the project we began dividing it up into the various subtasks that need
to be completed. So far we have 4 main tasks which we are tackling: collecting the data set of audio files, using
MFCC to collect all coefficients, using DTW to match audio files, and finalizing some type of classification
algorithm to match phonemes.
1) In terms of collecting the data set we need to gather the various audio files/songs that we want to be able
to do the voice translation for. We are probably going to just take maybe 10-15 second clips so there isnt too
much computational time. We also need to gather a recording of one of us saying the phrase which has 44 phonemes
and verify that they all are seen.
2) As of now we are planning to pursue using MFCC to be able to identify the various phonemes/audio. Previously
there was no builtin matlab toolbox to collect the phonemes which would’ve required us to use some library to
perform it. However, the latest version of matlab comes with a MFCC toolbox so we plan to use that and see if
it can adequately differentiate the phonemes.
3) We also plan to use DTW, dynamic time warping to or some other procedures to be able to reconfigure, adjust
the audio signals which are skewed in time. There is a matlab toolbox for this so should not be too difficult.
4) The biggest challenge will be finding the right type of classification algorithm which we can use to actually
determine which phonemes exist in the input audio file. This will require extensive research and time since most
of our group are not familiar with machine learning concepts. However, we are currently evaluating K-nearest
neighbors and some Bayesian algorithms and will hopefully be able to empty one of them.
4) New Concept/Tool
One new tool/concept that we learned about in this project is MFCC or Mel Frequency Cepstral Coefficients as we
mentioned before. MFCCs are commonly used in speech recognition applications and music information retrieval
applications which is more relevant to us. The reason MFCCs are so useful are that they can extract key identifiers
from an audio file in the form of coefficients which can then be used to evaluate/analyze that audio. The actual
procedure of MFFC is the following steps taken from Wikipedia:
1. Take the Fourier transform of (a windowed excerpt
of) a signal.
2. Map the powers of the spectrum obtained above onto the mel scale,
using triangular overlapping windows.
3. Take the logs of the powers at each of the mel frequencies.
4. Take the discrete cosign transform of the list
of mel log powers, as if it were a signal.
5. The MFCCs are the amplitudes of the resulting spectrum.
Originally we thought we would need to perform each of these steps but then we realized there are some pre-existing
libraries that we can use which consolidate these actions. There also exists a matlab toolbox in the latest version
of matlab which includes MFCC computations. So we will likely use some combination of the library and built in toolbox
or chose one which gives us the better results.