Final Report
Objective
The initial objective of our project was to create an automated karaoke system. Essentially it would work by taking a
sample of the user’s voice and replacing the vocals in a track with the user’s voice. To achieve this we are experimenting
with phonemes which are unique sounds and of which there are 44 in the English language. We would accomplish our goal by
collecting the users phonemes from a sample input track. Then we would collect all the phonemes of the vocals from a song.
We essentially swap the user’s phonemes with the phonemes in the vocals and recreate the vocal portion of the song. Lastly,
we would apply the reconstructed vocals with the instrumentals to produce the final track.
High Level Overview
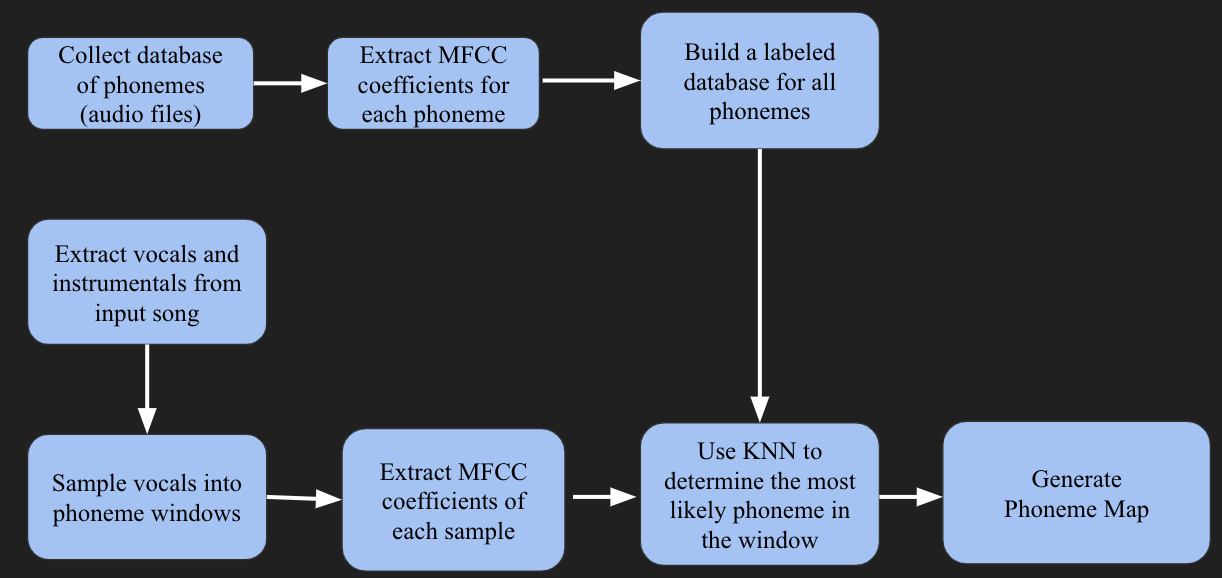
This figure breaks down a high level overview of how we will implement this system. The first step is to collect the
database of phonemes. We will then extract the MFCC coefficients for each phoneme which will allow us to identify and
distinguish the different phonemes. Then we will set up a labeled database that contains the MFCC coefficients for the
different phonemes. Now that we have the database built we can work with our song files. In terms of the songs, we first
use a software tool Audacity to extract the vocals and instrumentals. We then take the sample of the vocals such that
we look at small windows from which we try to predict the phoneme. We take the MFCC coefficients for each of these
small windows and then run this input against our database using the KNN classifier to predict the phoneme. Once we
have predicted all the phonemes we generate a map from the user’s phonemes to the phonemes in the song file and then
proceed to swap them.
Implementation
- Data collection
- Song Deconstruction - Audacity
- MFCC Coefficient Extraction
- Using KNN Classifier
- Audio Segmentation / Word Splitting
To collect the data for our phoneme dataset we essentially had multiple speakers say the 44 phonemes multiple
times and accumulated this data. We were able to generate over 600 audio files of data containing the phonemes.
From this raw data we then downsampled it by taking the highest power regions of the audio sample. These reduced
samples were then run through the MFCC toolbox and we collected the corresponding coefficients for each phoneme.
This was then built into a labeled dataset which used as our final database.
The tool we decided to use to take in a song and then split the vocals from the instrumentals was audacity.
Since we are only manipulating phonemes we only required the vocals from a given track. After tweaking and
investigating Audacities capabilities we found that extracting the vocals alone did not return clean results
as the audio files had a lot of noise. One technique that helped was taking original track and finding a track
that contained just the instrumentals and then subtracting the instrumentals from the track. This worked to some
extent but once again the results were audio files that were not very clear and given the lack of robustness in
our phoneme detection would’ve made it impractical to use.
The following figure was an attempt to extract the vocals from the original audio track. Upon playback we
found the vocals were quite noisy and would not have performed well in our phoneme extraction.
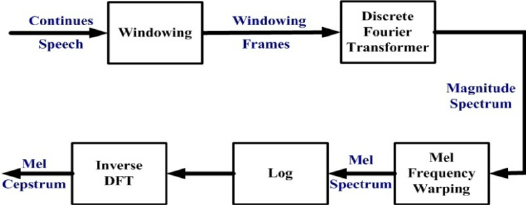
The specific tool that we are using to identify/ distinguish phonemes are Mel Frequency Cepstral Coefficients.
MFCCs are commonly used in speech recognition applications and music information retrieval applications which
is more relevant to us. The reason MFCCs are so useful are that they can extract key identifiers from an audio
file in the form of coefficients which can then be used to evaluate/analyze that audio.
The following image shows the steps required to extract the MFCC coefficients from an audio speech sample.
In our project we want to specifically extract the MFCC coefficients for phonemes. Therefore, our data set is
composed of the MFCC coefficients that identify each of the phonemes. Initially we were trying to extract the
coefficients using Matlab’s built in MFCC toolbox. However, we began to see that we were getting unusable values
for the coefficients. All of the coefficients for a lot of phonemes were very close to each other and we couldn’t
actually distinguish between the phonemes. This made our project very difficult because we could not perform
identification which meant of course that we could not classify the phonemes from an input audio sample.
In later experimentation we found an external MFCC library and noticed that we were getting better results.
This outside library allowed us to receive much better results in which we could distinguish more phonemes.
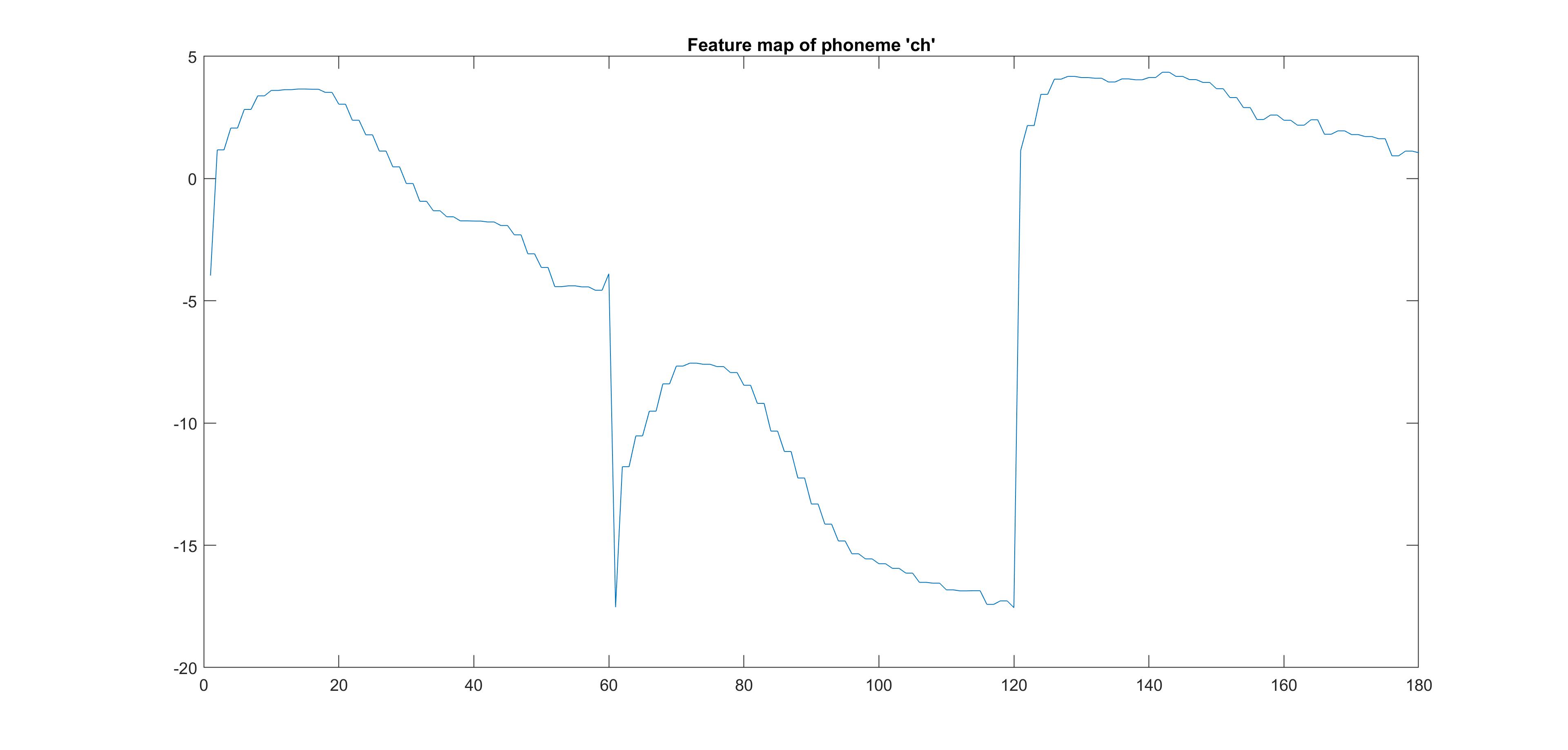
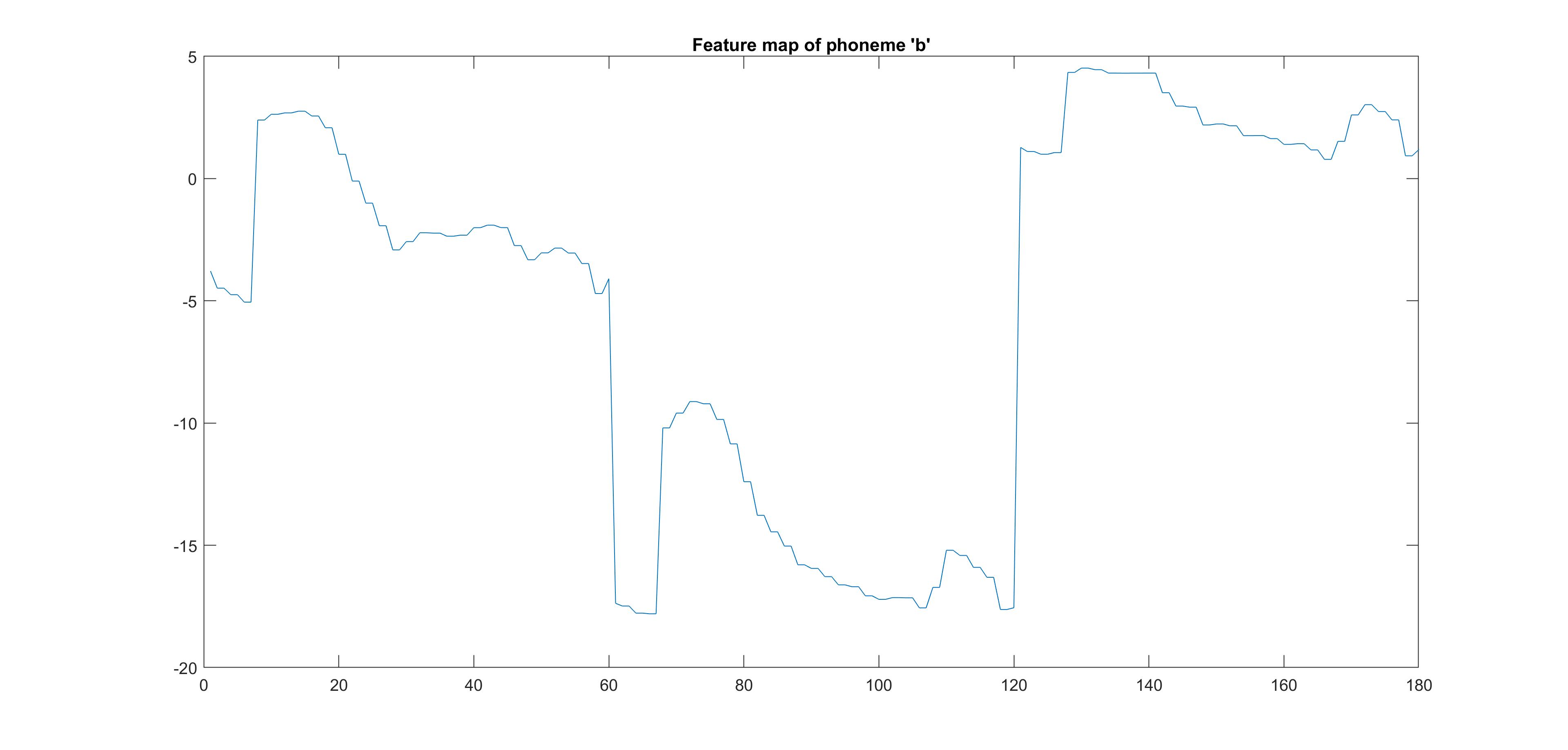
The following images show the feature maps that we generated for the phonemes “ch” and “b”. We noticed that
some phonemes were very similar to others in terms of their feature vectors and this created challenges for
us in being able to distinguish between certain phonemes.
We chose to use a KNN classifier and pattern recognition algorithm due to the lack of experience and training in machine learning that the group had and its recognition of patterns using non-parameterized data. Early on, we identified the high potential similarities in feature maps of the MFCC coefficients and attempted many differing variations on the KNN classifier. Sweeping across both K values and distance calculations lead to a normalized K value of 15, small deviations for K values of 10 to 20 and a euclidean distance. Utilizing the database, we generated predictions on “unlabelled” data and generated a probability of correct predictions.
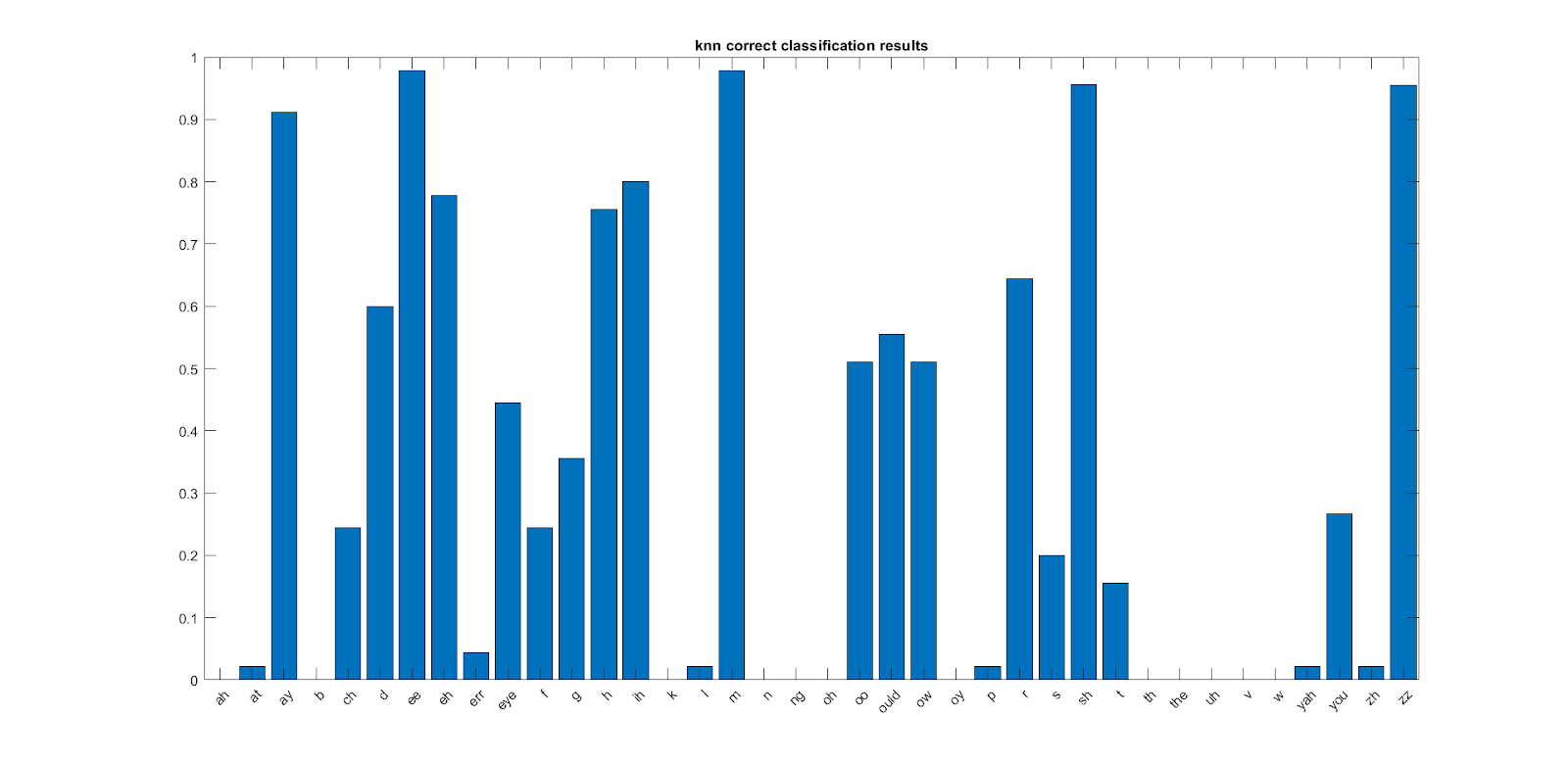
Here we can see that some of the phonemes are highly detectable and highly accurate in the KNN classifier.
Although this seems highly promising, this should be taken with a grain of salt as each phoneme should have
similar probability given the nature of their feature maps. It is probable that the KNN algorithm is classifying
similar phonemes into another group. One of the many drawbacks from KNN is that it is lazy and can generate
groups that are too similar in nature and unable to distinguish when input data into the KNN model is too similar.
Phonemes are generally classified into subparts, vowels, consonants, etc. and these are most likely being
suppressed and classified as the dominant and highly detected phoneme.
With further time and opportunities, utilization of a new pattern recognition algorithm could prove fruitful as
well as understanding the methodology to choosing an appropriate K. Additionally, attempts at denoising data
hasn’t shown any signs of failure yet and would most likely be a great opportunity to improve the uniqueness
of each phoneme.
One of the aspects of this project we tried to tackle was splitting a sentence into words. We found that this proved to be a very difficult task. For splitting a normally spoken sentence alone there were a lot of challenges which are even more prominent in the vocals of a song. For songs sometimes there are fast and slow sections and a lot of words are even slurred together. In the attempts to try to split our input audio file sentences into audio files containing just the words we tried to different tools. One tool was trying an envelope detection scheme in Matlab where we set a threshold for the magnitude of the audio sample and try to find regions of silence to separate the words. The following image shows an attempt to separate regions of pronunciation using this method.
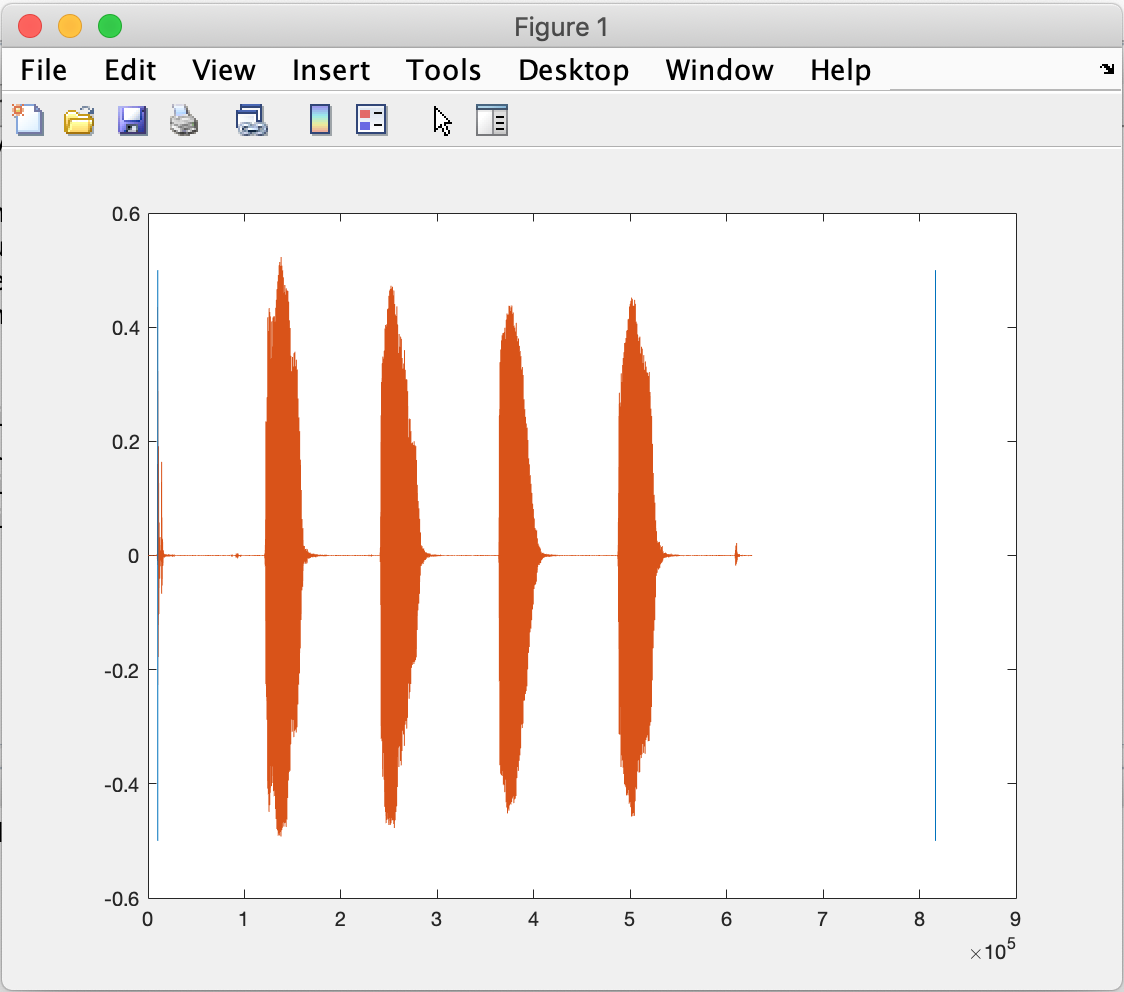
We experimented with different thresholds and parameters but it would never accurately determine where a
word begins and ends. In this case it would just indicate the beginning and end of the audio file as seen
by the blue lines.
We tried another tool in Python called pydub which is capable of manipulating and working with various audio
files. This module has a capability called split_on_silence which once again tries to find regions of the signal
with minimal amplitude as a means of splitting the signal into words. Once again this tool also had various issues
and would never generate the individual audio files for separate words.
We learned from these tests that audio segmentation especially detecting words is not a trivial problem and
requires a lot more work and testing.
Problems/Challenges
In tackling this project we ran into a lot of different challenges that forced us to greatly limit the scope of what
we could accomplish. One of the major challenges that we faced was that majority of our project was based on being able
to collect good data using the MFCC technique. We spent a lot of time trying to manipulate the different parameters and
settings in the Matlab toolbox for MFCC to try and get better results but they were not working out. The major issue was
that this toolbox was generating very similar coefficients for many of the phonemes to the point that we could not actually
distinguish between the different phonemes. This cascaded to the rest of the project to the point where we could not make
progress on a lot of the other steps we needed.
Eventually we switched from using the Matlab toolbox to an independent MFCC library and this had some slightly better
results. Ultimately when we ran the database against input phoneme samples using KNN we were getting an accuracy of about
30% but we feel this can definitely be improved.
Another difficult task in this project we did not anticipate is actually taking the vocals of a song and segmenting/windowing
it properly to extract/ predict the phonemes. This was a particular challenge because it was difficult to determine how
long to make the sample to be able to capture the individual phonemes that comprised a word or sentence. This was further
difficult since some phonemes extended to be longer in time than others. We believed Dynamic Time Warping might have solved
this but were not able to condense the signals enough to use it.
Also we attempted to break down the vocals into words to allow for simpler audio files from which we could attain the phonemes
but as discussed above this was very difficult to implement for a song where many words are often slurred together.
Future Improvements
The following are some of the various techniques and procedures we would try to improve this project in the future.
Course Tools Used
The two DSP course tools we used for the project are a moving average filter and frequency domain representations of signals.
We also implemented a K Nearest Neighbor classifier, which helped us predict phoneme features.
References
MFCC-GMM Based Accent Recognition System for Telugu Speech Signals
https://link.springer.com/article/10.1007/s10772-015-9328-y
High Quality Voice Morphing
https://ieeexplore.ieee.org/document/1325909
Voice Morphing System for Impersonating in Karaoke Applications
http://www.cs.cmu.edu/~dod/papers/cano00voice.pdf